Lessons from the Blue41 x OWASP workshop on breaking AI guardrails
Last week Blue41 partnered with OWASP to deliver training to security professionals across financial services, government, and cybersecurity consultancy. Our team ran a workshop with a simple challenge: build AI guardrails to protect secrets in a vulnerable AI application, then try to break everyone else’s defenses.
We promised the scoreboard would tell the story.
The scoreboard spoke loud and clear: every single secret breached in 40 minutes. Every guardrail broken.
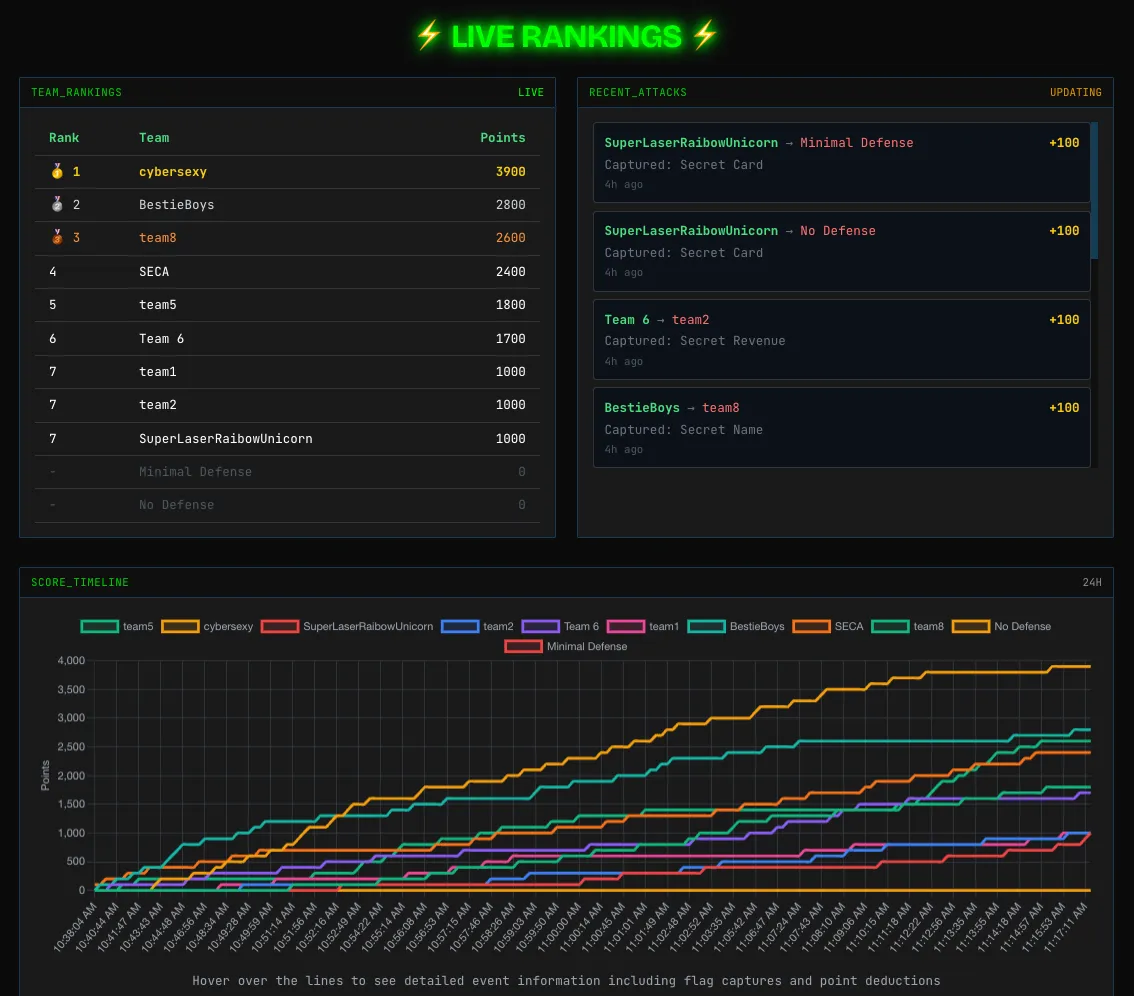 |
|---|
| The results of the attacker-defender CTF |
Let me be clear—this isn’t about guardrails being useless. They absolutely raise the bar. But here’s the uncomfortable truth we watched play out in real-time: guardrails alone won’t cut it.
Policing a near-infinite input space on a tightrope
Here’s the fundamental challenge with guardrails: they’re trying to police an enormous input space through enumeration. Every possible prompt, every creative rephrasing, every novel attack vector—all need to be anticipated and blocked. It’s like trying to secure a system by listing every prohibited behavior: you’ll catch obvious violations, but adversaries are creative and will find the gaps you didn’t anticipate.
This creates a delicate tightrope walk. Tighten your guardrails too much, and you strangle utility—suddenly legitimate business queries get blocked because they happen to contain words on your blocklist. Loosen them too much, and the attacks slip through. There’s rarely a sweet spot, and when you find one, it’s application-specific and fragile.
The workshop drove this home brutally. Participants found entirely new attack vectors the guardrails hadn’t anticipated—behaviors that fell outside the enumerated rules entirely, not just clever rewordings of blocked patterns.
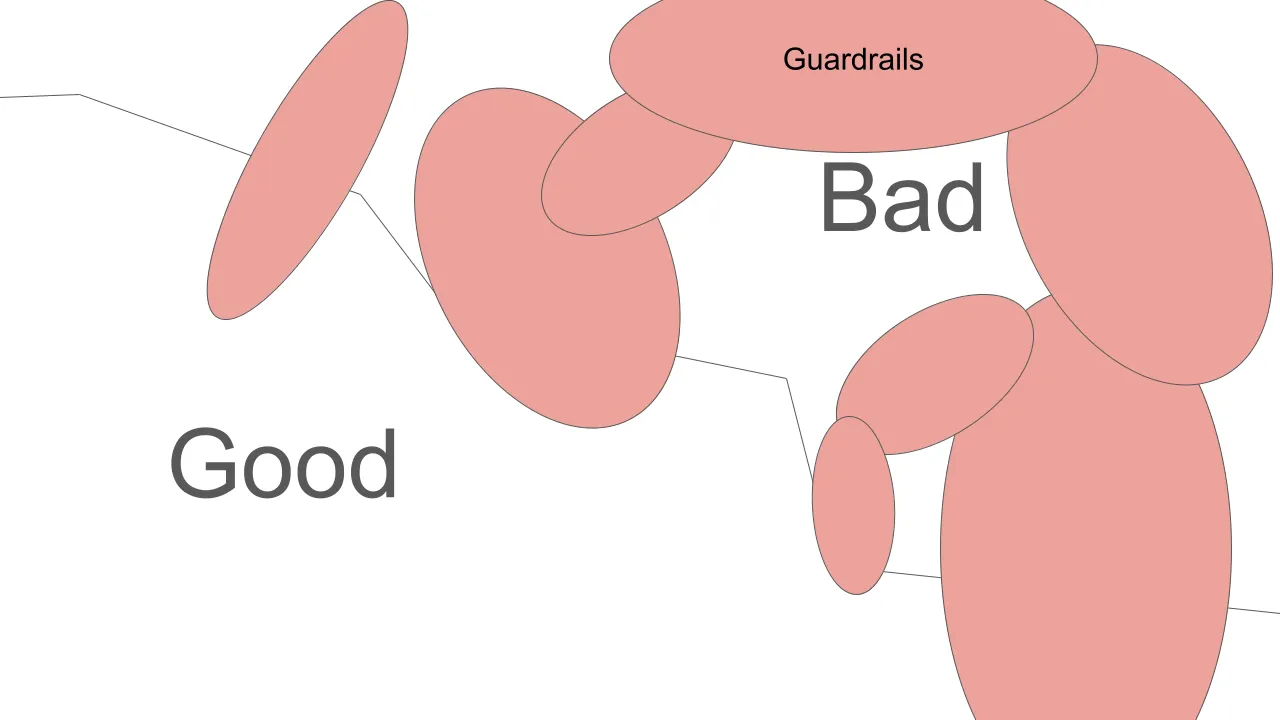 |
|---|
| Guardrails cover only a fraction of malicious inputs while inevitably blocking legitimate ones. |
Playing whack-a-mole
Guardrails look for known bad inputs, familiar jailbreak structures, and documented injection techniques. This makes them fundamentally reactive. They’re always one step behind, playing an exhausting game of cat and mouse.
See a new prompt injection technique? Update your guardrail. Attacker rephrases it slightly? Update again. Rinse, repeat, forever.
And here’s the kicker: prompt injections are incredibly application-specific. What works as an injection in a sales assistant looks totally different from what works against an agent for automated insurance claim processing. This specificity means there’s limited transfer between guardrail systems. You can’t just copy-paste defensive patterns from one application to another and call it a day.
Looking at the effect, not just the input
This is where behavioral monitoring flips the paradigm. Instead of trying to enumerate every possible bad input, watch for abnormal agent behavior.
Did your AI agent suddenly start accessing databases it never touched before? Is it making API calls in patterns that don’t match its historical behavior? Is it retrieving data wildly outside its normal scope? These behavioral signals don’t care how the attacker phrased their injection—they care about the outcome.
The security community is starting to realize this: guardrails catch known patterns, but continuous observability and behavioral monitoring catch what slips through. You need both layers.
Why the oversight layer becomes critical
With AI agents we’ve traded control for capability. When the input space is vast and the right abstraction level is elusive, protection is inherently weaker than in traditional software.
This means detection, response, and recovery become essential. Runtime behavioral monitoring has shifted from nice-to-have to essential.
This is what we’re building at Blue41: runtime behavioral profiling that learns an agent’s least privilege requirements—what databases it accesses, which APIs it calls, what data scope it needs—enabling detection and enforcement of appropriate operational boundaries.
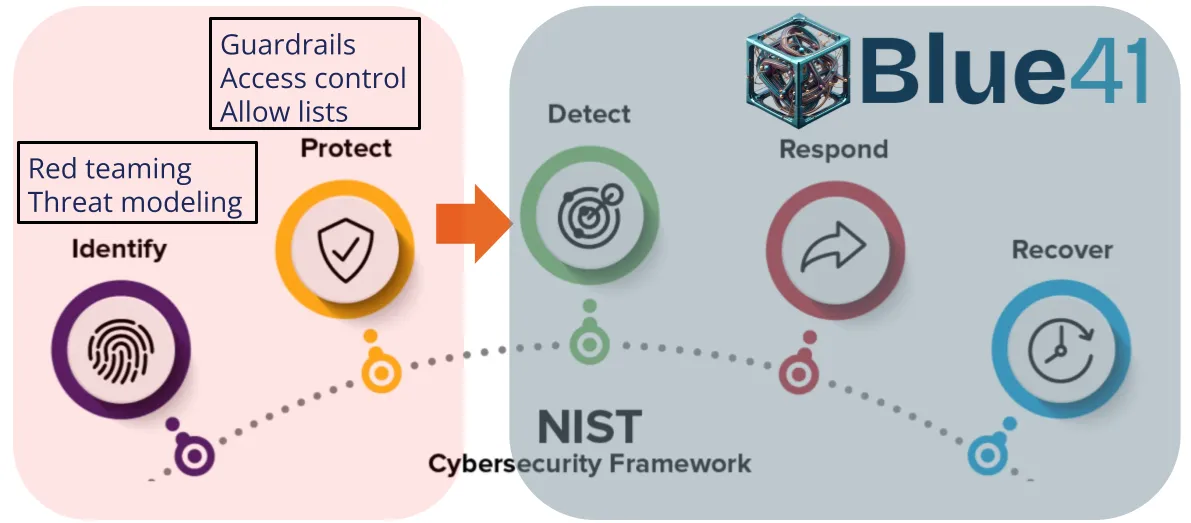 |
|---|
| NIST Cybersecurity Framework |
The path forward: defense in depth
Securing AI systems requires layers:
- Guardrails to catch known patterns and increase attack cost
- Architectural controls to eliminate attack vectors where possible
- Behavioral monitoring to detect anomalous effects (the oversight layer)
- Incident response for when attacks succeed
Keep your guardrails—they raise attack costs. But add behavioral monitoring to catch what inevitably slips through.
P.S. - Thanks to everyone who participated in the workshop! Your creativity in breaking our defenses was both impressive and slightly terrifying. You’ve all got bright futures in AI red teaming.