Hallucinations: LLMs' major reliability problem
Despite their impressive capabilities, large language models (LLMs) present significant challenges when organizations move from a prototype to a production-grade AI deployment. One of the most critical concerns is reliability, particularly in the form of “hallucinations”—instances where LLMs generate responses that look plausible but are factually incorrect.
The role of retrieval-augmented generation
One pivotal approach for improving the reliability of LLM-based applications in real-world settings is Retrieval-Augmented Generation (RAG). RAG works by integrating external knowledge sources into the model’s generation process. This allows the LLM to retrieve relevant information in real-time, enhancing the accuracy and grounding of its output. According to Gartner1, RAG is now considered a key design pattern for improving the precision of LLM responses, making it a common strategy for enterprises leveraging generative AI.
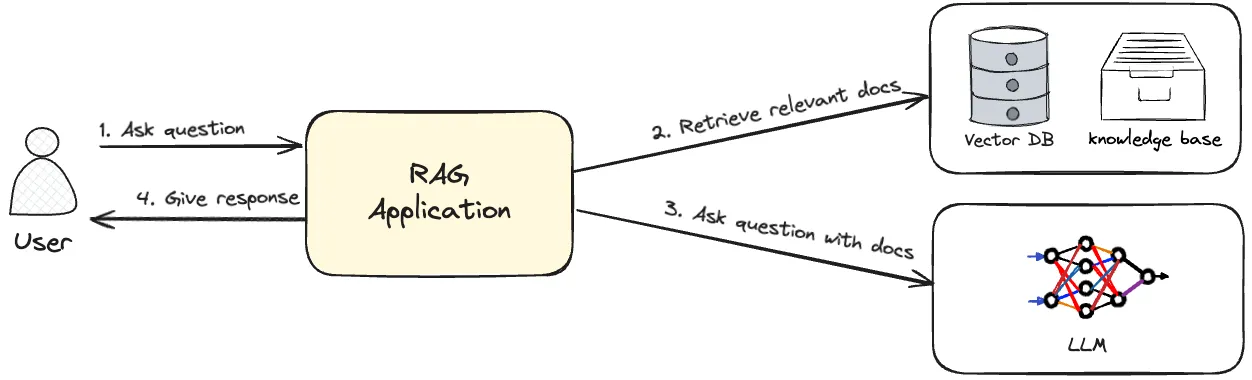 |
|---|
| Architecture diagram of a Retrieval-Augemented Generation (RAG) application |
Not foolproof: hallucinations in RAG applications
Although RAG aims to mitigate hallucinations by grounding responses in retrieved data, studies show the problem remains prevalent. Recent research from Stanford University on AI legal tools2 defined misgrounded RAG hallucinations: responses where statements either arise from a misinterpretation of the context or present facts that are not part of the context at all. Overall, the researchers found that although using RAG reduces hallucinations, they still occur in 17% to 33% of cases when applied to AI-based legal research tools.
Real-world example of a hallucination
To illustrate RAG hallucinations more clearly, we present a real-world example involving GPT-4o. We show that despite
having relevant retrieved context, a state-of-the-art LLM can still fail, even for seemingly trivial
tasks. Consider a scenario involving a RAG-powered chatbot. A user asks the chatbot about the visiting hours
for the company’s Berlin office. The retrieval process finds a relevant document listing contact details for all office
locations. However, the Berlin office explicitly has no set visiting hours. Despite this accurate retrieved
data, GPT-4o generates a response with hallucinated visiting hours.
Below, we list the interaction with the LLM, but you
can observe this issue firsthand by running the example in OpenAI’s playground.
System and user prompt
Please answer the following user question, using the provided context documents.
--- CONTEXT DOCUMENTS ---
...
London Office
Address: 22 Baker Street, W1U 3BW London, United Kingdom
Phone: +44 20 7153 4567
Email: london.office@company.com
Visiting Hours: Monday to Friday, 9:00 AM - 6:00 PM GMT
Berlin Office
Address: 31 Friedrichstraße, 10117 Berlin, Germany
Phone: +49 30 2345 6789
Email: berlin.office@company.com
...
--- USER QUESTION ---
During which hours can I visit your Berlin office?
GPT-4o’s Answer
You can visit the Berlin office from Monday to Friday, 8:00 AM to 5:00 PM CET.
| Example of an LLM hallucinating in a RAG context. At the top, you can see the system prompt, followed by the user prompt which contains both the retrieved documents and the user’s question. At the bottom, you can see the hallucinated response. |
The impact of unreliable applications
Although the example above may seem trivial, such hallucinations can still lead to misinformation with serious consequences. This risk is naturally heightened in sensitive or business-critical applications, such as AI-driven legal, accounting, healthcare diagnostics, financial advising, or regulatory compliance tools. Inaccurate AI-generated responses can damage customer relationships, harm a company’s reputation, and expose the business to compliance risks. The reliability of AI in customer interactions is crucial to maintaining trust and preventing costly errors. For internal-facing applications, unreliability can harm business by leading to incorrect decisions and flawed analyses. Because hallucinations often appear credible to an end-user, their consequences may go unnoticed for extended periods, increasing the potential for harm.
Mitigating Hallucinations: The Role of LLM-as-a-judge
It is clear that addressing hallucinations is essential for successfully adopting LLM technology in enterprise environments. Implementing observability tools capable of detecting hallucinations provides the foundation for effective mitigation.
One promising detection strategy involves using another LLM to verify the accuracy of outputs, a concept known as LLM-as-a-Judge3. Our research indicates that this approach yields promising results. However, building a high-performance detector requires optimized prompt engineering, incorporating techniques such as Chain-of-Thought (CoT) prompting. Additionally, fine-tuning models on datasets that capture hallucinations further has shown to increase detection rates. As part of our commitment to the community working to productionize RAG-based applications, we have released a demo of a hallucination detector as an easy-to-integrate API.
Using a hallucination detector
Organizations can use this API to evaluate the outputs of their RAG applications. The detector determines whether the output aligns with the context, along with reasoning for why it does or doesn’t.
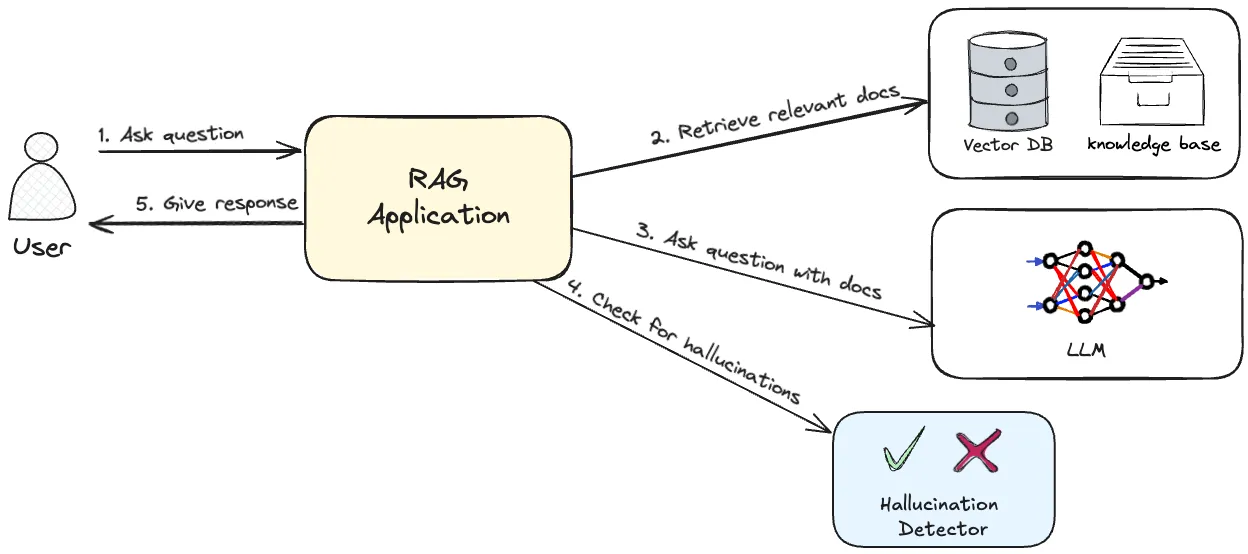 |
|---|
| Architecture diagram of a RAG application with a hallucination detector |
In most cases, this detection call should be executed after the LLM generates its full RAG response. The result can then be used to adjust the control flow of the application, such as preventing a hallucinated response from being shown to the user.
If we run the hallucination detection API on the GPT-4o example above, it successfully flags the hallucination. Here’s the output:
{
"is_hallucination": True,
"reasoning": "- The QUESTION asks for the visiting hours of the Berlin office.
- The DOCUMENT provides information about the Berlin office, including its address, phone number, and email, but does not specify the visiting hours.
- The ANSWER states that the Berlin office can be visited from Monday to Friday, 8:00 AM to 5:00 PM CET.
- Since the DOCUMENT does not provide any visiting hours for the Berlin office, the ANSWER introduces new information that is not present in the DOCUMENT.
- Therefore, the ANSWER is not faithful to the DOCUMENT as it provides details not supported by the given text."
}
This output demonstrates how the hallucination detector not only identifies when an LLM generates misgrounded information but also explains the reasoning behind its decision. Such insights help organizations understand and manage reliability risks.
Conclusion
Mitigating hallucinations in LLM-based applications is critical for ensuring the reliability of AI-powered systems. Architectures like RAG help ground model outputs in external data, but they are not entirely free from hallucinations. Combining RAG with techniques like LLM-as-a-Judge can further enhance accuracy by verifying the factual consistency of responses before they reach end-users. These strategies are essential for enterprises that want to leverage AI, in production-grade settings.
If you would like to try out a hallucination detector, check out the code example below or consult the API documentation. If you want to learn more about AI reliability or have a question, don’t hesitate to reach out to us.
Appendix: Code example
import requests
# 1. First, sign up to get an API key
email = "your-email@example.com"
resp = requests.post("https://api.blue41.com/signup", json={"email": email})
print("Check your email for the API key." if resp.status_code == 200 else f"Error: {resp.status_code}, {resp.json()}")
# 2. Use the API key to detect hallucinations
API_KEY = 'your-api-key-here'
data = {
"question": "During which hours can I visit your Berlin office?",
"answer": "You can visit the Berlin office from Monday to Friday, 8:00 AM to 5:00 PM CET.",
"context": " ... London Office ... "
}
resp = requests.post("https://api.blue41.com/demo/rag-hallucinations", json=data, headers={"x-api-key": API_KEY})
if resp.status_code == 200:
result = resp.json()
if result['is_hallucination']:
pass # Implement hallucination mitigation here, e.g. blocking the response
else:
print(f"Error: {resp.status_code}, {resp.json()}")