Unmasking Prompt Injection Attacks
As AI development continues rapidly, large language models (LLMs) have become crucial to our digital landscape. These models power applications ranging from chatbots to autonomous agents. But while their potential is immense, they enlarge the threat surface of the applications they power. One of the most examined threats to LLM application security is a type of cyberattack known as a prompt injection. This article explores prompt injections, the difference with jailbreaks and the defensive measures you can take to protect your LLM-powered systems.
What Are Prompt Injection Attacks?
A prompt injection is an attack vector where an adversary manipulates the input of an LLM and injects malicious instructions, causing the model to perform unintended actions. These actions can range from generating harmful content to leaking sensitive information or manipulating downstream processes.
Prompt Injection vs. Jailbreaking: Understanding the Difference
While the terms prompt injection and jailbreaking are often used interchangeably, they represent different concepts.
- Prompt injection is an attack vector against deployed LLMs that occurs due to a poor separation of control and data plane. Prompt injections can be used to achieve various attacker goals.
- Jailbreaking implies a specific attacker’s goal: bypassing the LLMs’ safety mechanisms. Jailbreaking does not necessarily happen through prompt injection.
It seems straightforward, right? But to fully understand why these terms are sometimes confused, let’s look at the recent history of large language models (LLMs).
When instruction-tuned LLMs—models capable of following user instructions—became publicly accessible through chatbots, concerns arose over how this powerful technology might be misused. Developers were apprehensive about issues like the automated generation of malware, large-scale misinformation, and the easy availability of dangerous information (e.g., instructions for making hazardous substances like napalm).
Developers added several countermeasures to LLM-based chat models to address these safety concerns. These included safety training, system-level prompts, and content filters, all designed to ensure that chatbots behaved “ethically”—at least within certain boundaries.
However, users quickly found ways to circumvent these safeguards through what became known as jailbreaking. Jailbreaking allows users to “free” chatbots from their restrictions, enabling them to discuss topics or perform actions that the model’s creators had intentionally blocked. To this end, adversaries would invent creative prompts to trick the chatbot (prompt injections) 1 or poison its training data 2. Training data poisoning installs a backdoor during the training phase of the model. Once the model is deployed, this backdoor can be triggered later by including a specific keyword in the input.

On the other hand, prompt injection is a broader attack methodology. It’s not limited to just breaking LLMs out of their safety protocols. As LLMs are increasingly used to automate more critical and complex tasks beyond chatbots, malicious prompts can be injected for other nefarious purposes, such as phishing, leaking confidential data, or executing malicious code.
In conclusion, jailbreaking is a specific attacker goal—circumventing the model’s built-in safety features. Prompt injection is an attack method that can be used to achieve that goal. Importantly, prompt injection attacks have a more diverse impact, not limited to jailbreaking!
The Growing Threat of Indirect Prompt Injection
Prompt injection attacks don’t always need to be carried out directly by the end user. In an indirect prompt injection, the attacker is a third party who introduces malicious instructions through external data sources that the LLM processes.
For instance, consider an LLM designed to screen résumés and filter candidates based on specific job requirements. This system could be vulnerable to an indirect prompt injection if a candidate embeds hidden instructions in their résumé, directing the LLM to pass them through the screening process. In this case, the candidate becomes the attacker, manipulating the system to gain an unfair advantage.
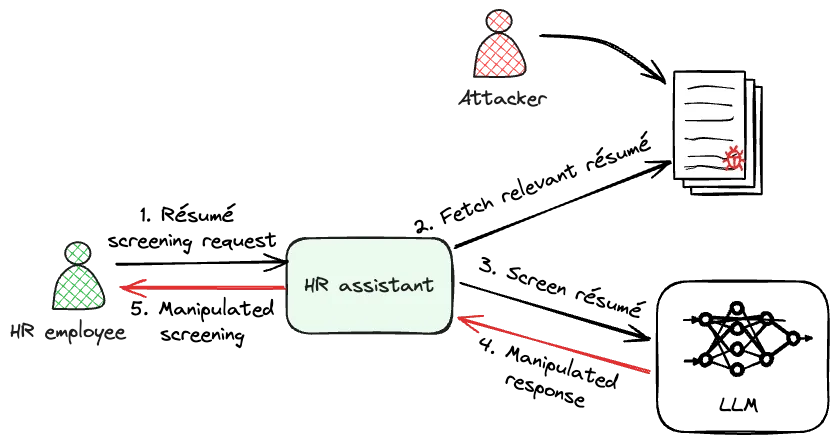 |
|---|
| Example of an indirect prompt injection attack on an HR assistant that screens résumés. |
Indirect prompt injections are a significant threat to LLM-powered applications (check out this blog post on real-world attacks), especially those that rely on external data to enhance performance. One such architecture is Retrieval Augmented Generation (RAG), which boosts the accuracy of LLM outputs by retrieving contextual data from various sources. While this improves utility, it also opens the door for adversaries to inject harmful instructions through the retrieved data.
To learn more about how RAG relates to LLM hallucinations, check out our blog post on hallucinations in LLMs.
In summary, indirect prompt injection attacks involve a third-party attacker. In contrast, when the end user is the attacker, it’s referred to as a direct prompt injection.
Mitigating Prompt Injection Risks: Current Approaches and Challenges
Mitigating prompt injection attacks remains challenging due to the way Large Language Models (LLMs) process inputs as a unified text block, without differentiating between instructions and external data. This ambiguity complicates the task of distinguishing between legitimate and malicious inputs. To address these risks, it is essential to adapt established security best practices—such as threat modeling, red teaming, least privilege, and detection & response—to applications powered by LLMs.
One early example of indirect prompt injections involved exfiltrating user data through the loading of images3. This vulnerability was mitigated by disabling image loading from untrusted domains, a countermeasure that aligns with minimizing unnecessary application capabilities. Other best practices such as threat modeling and red teaming allow to capture such vulnerabilities early. Although such precautions reduce risk, vulnerabilities can still arise even when best practices are followed. Additionally, removing certain capabilities may limit the application’s functionality, driving researchers to seek new detection methodologies specific to prompt injection.
The scientific literature proposes several approaches for detecting prompt injections, with two notable methods highlighted here. The first involves detecting prompt injections by analyzing input patterns and comparing them to known attacks 4. While effective, this approach requires the expertise of threat hunters to maintain the detection system and can be restrictive when modeled as a classifier, as it is difficult to model the benign class. A second approach—less reliant on known exploits, detects task manipulation through task drift monitoring 5. This method captures changes in the internal workings of the model when an adversary tries to inject new instructions, i.e., change the intended task.
Concluding Remarks
As we integrate large language models (LLMs) into various applications, it’s crucial to consider the threat model, which captures the adversaries’ goals, capabilities, and knowledge. This understanding is essential for designing effective mitigation strategies and ensuring the security of LLM-powered systems. By proactively identifying vulnerabilities and implementing robust detection and response, we can better protect the evolving threat surface of our exciting new applications.
We help organizations understand and mitigate AI risks. Contact us to learn more.
References
Footnotes
-
Shen, Xinyue, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. “Do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models.” arXiv preprint arXiv:2308.03825 (2023). To appear in CCS 2024. ↩
-
Rando, Javier, and Florian Tramèr. “Universal Jailbreak Backdoors from Poisoned Human Feedback.” arXiv, April 29, 2024. https://doi.org/10.48550/arXiv.2311.14455. ↩
-
Singh, Sandeep, “How a Prompt Injection Vulnerability Led to Data Exfiltration.” HackerOne, April 29, 2024. https://www.hackerone.com/ai/prompt-injection-deep-dive. ↩
-
Wan, Shengye, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, et al. “CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models.” arXiv, August 2, 2024. https://doi.org/10.48550/arXiv.2408.01605 ↩
-
Abdelnabi, Sahar, Aideen Fay, Giovanni Cherubin, Ahmed Salem, Mario Fritz, and Andrew Paverd. “Are You Still on Track!? Catching LLM Task Drift with Activations.” arXiv.org, June 2, 2024. https://arxiv.org/abs/2406.00799v4. ↩